Main content
Top content
Neural Architecture Design
What drives the ever increasing predictive power of Convolutional Neural Networks that dominated Image classification in recent years?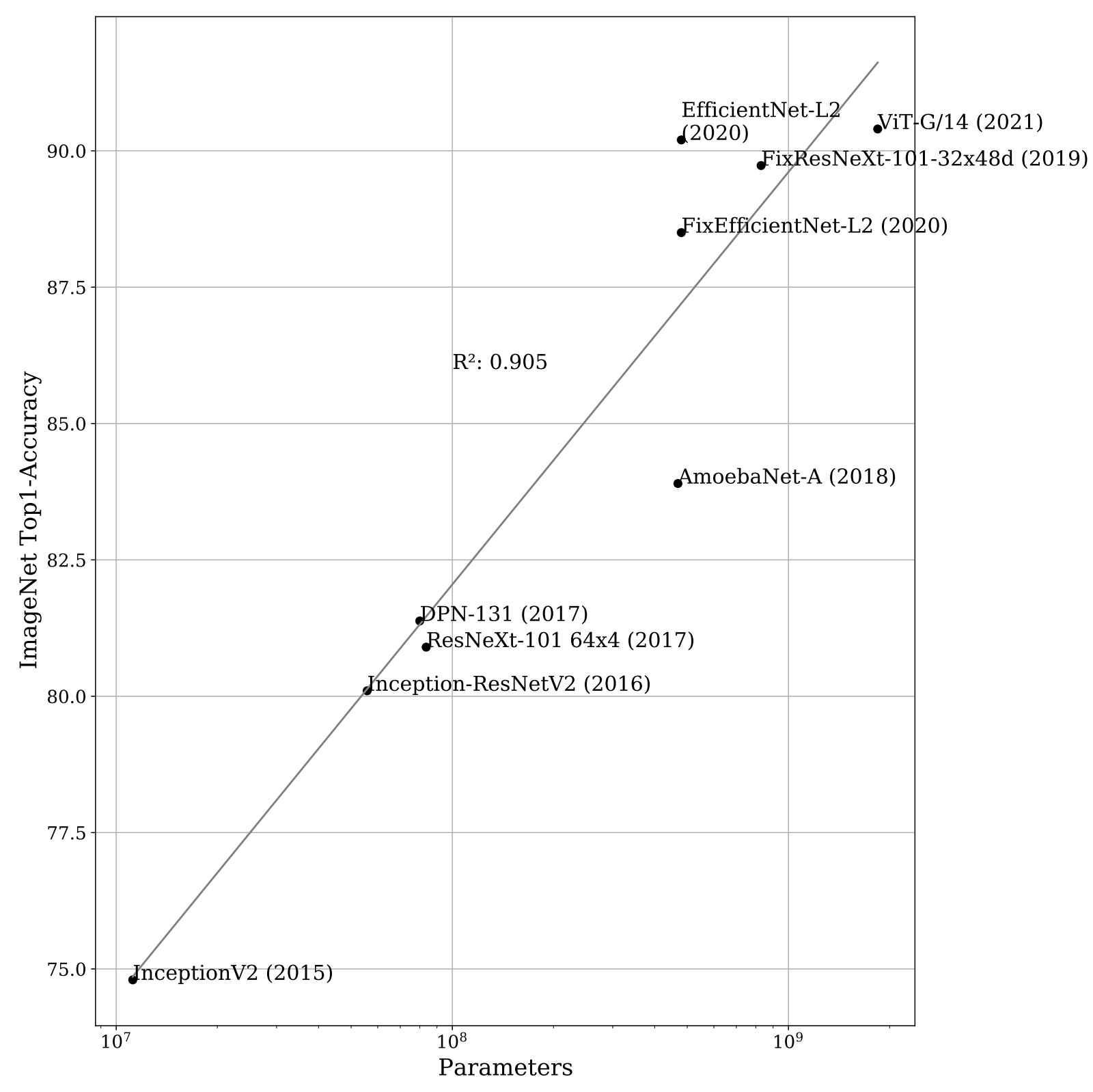
Many publications propose novel “state-of-the-art”-architecture with various novel architecture ideas. However, the design process behind these remains inherently founded in expensive comparative evaluation combined with trial-and-error. When looking at the complexity (measured in parameters) state of the art architectures over the years it is apparent that the incremental improvements were made possible primarily by an exponential increase in parameters.
Performance gains by exponentially increasing the models complexity and thus the computational resources required to process them detaches these design procedures from real-world application, where resources are often as expensive as they are limited.
Therefore the current situation is that and expensive design process produces increasingly expensive solutions to the problem of Image Classification.
The main reason for this is that convolutional neural networks are neither self-evident in their behavior nor human readable.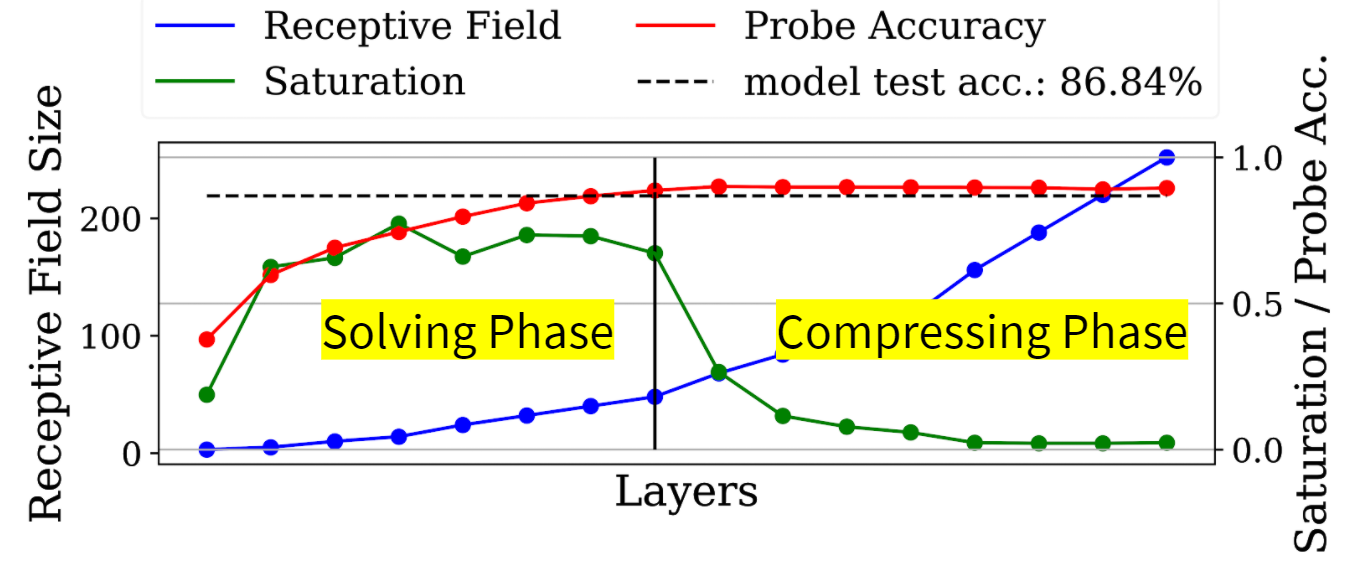
In order to move towards a well informed (and thus less trial-and-error-heavy) design process, novel analysis methodologies are required.
These methodologies should allow for the identification of inefficiencies within the neural network structure and the training setup.
The goal of the project is to develop such techniques and develop pathologies that allow for quick and easy evaluation of neural architecture design.
So far, we have been able to identify unproductive sequences of layers by using logistic regression “probes” and PCA to analyze the intermediate solution quality and processing happening in hidden layers.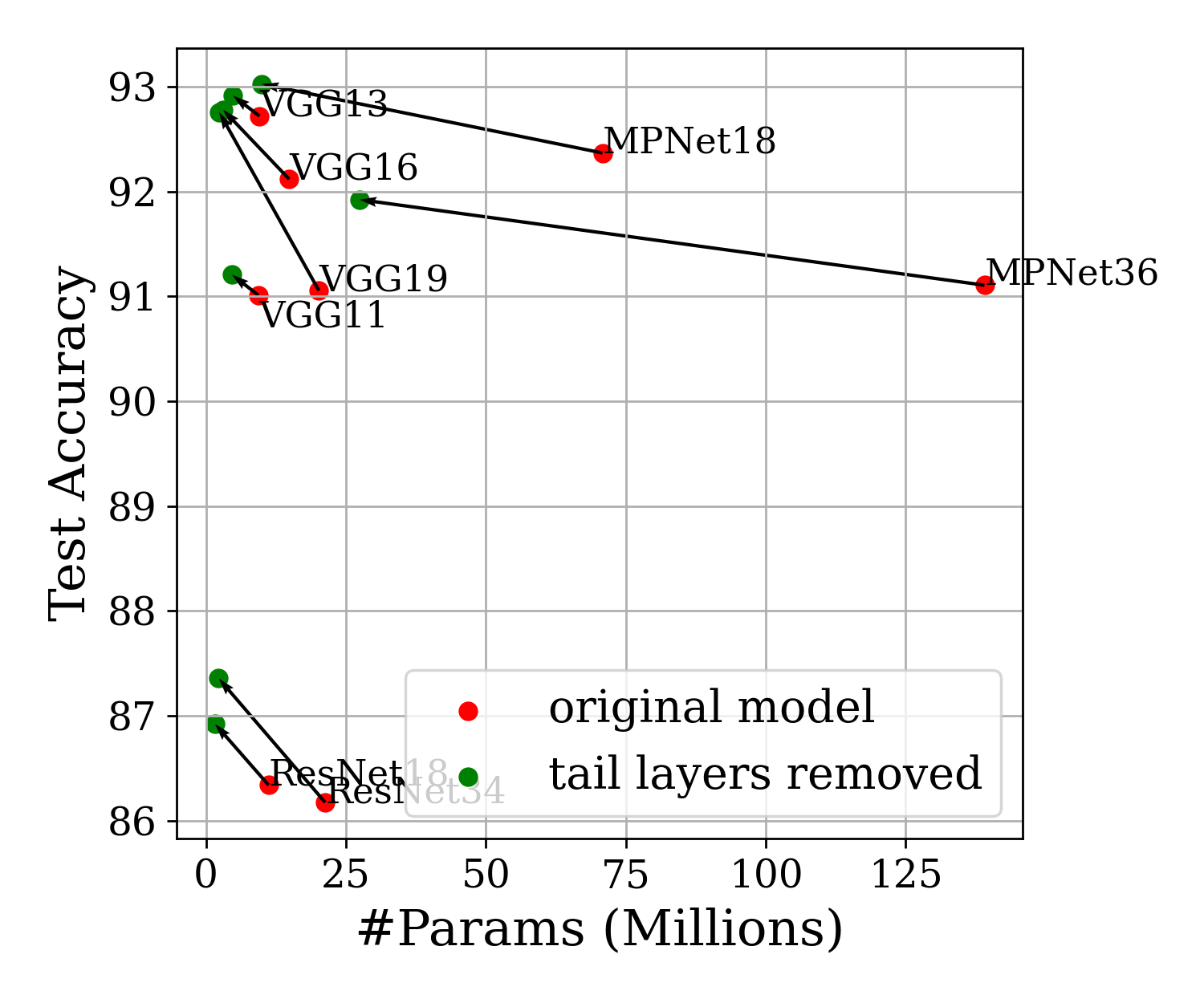
Based on these analyses we find that in certain circumstances unproductive sequences of layers emerge reliably during training that can be simply cut from the architecture.
Recently we were also able to predict these inefficient solely based on information known prior to training.
Optimization steps derived from these analyses show reliable improvements in reduction of parameters and improvements in predictive performance, making the network more efficient and more reliable.
